

This use case was initiated in collaboration with the Data Sharing working group of the Dutch AI Coalition (NL AIC), one of the founding partners of the CoE-DSC.
Data sharing is the new multiplying. Only how can we do this in a controlled way? The European data strategy sees a number of threats “Currently, a small number of large technology companies control a large part of the world’s data. This could discourage other data-driven companies from starting, growing or innovating in the EU”.
Data, together with algorithms, is the building block for AI applications. Though our handling of data is somewhat ambivalent. In private situations we see that people have no problem using applications that also use data for other purposes. In an organisational setting we see that data is strictly protected. Not an illogical way of thinking: data represents value or it is not allowed to make data available because of privacy laws. However, in this way valuable data remains in silos and meaningful AI applications cannot be (easily) realised.
Design data part infrastructure
The report ‘Responsible data sharing‘, published in March 2020, described the need for a data sharing infrastructure. In this report, a prelude was made to what this infrastructure could look like in order to stimulate AI in the Netherlands.
Good news: there are methods and techniques available whereby the data owner retains control over the data. It is also an option that data does not have to be shared, but that this is limited to the results of an algorithm which ‘travels’ along the data sources. With these kinds of solutions, AI applications can be provided with more and better information. To demonstrate this, a number of technical ‘Proof of Concepts’ (PoCs) have been carried out together with the application areas of Health and Care, Public Services, and Energy and Sustainability, whereby so-called ‘ecosystems of trust’ have been set up in practice.
Proof of concept Health and Care
On this page we will elaborate on the proof of concept in healthcare. By means of two use cases, namely the analysis of photographs and lab results focused on COVID-19, it has been demonstrated which solutions are options to responsibly share data in practice. This collaboration was established with participants from various organisations including the EMC, LUMC, Health RI, GO-FAIR, UT, TNO and the working groups Health and Care and Data Sharing of the NL AIC.
Ecosystem
Privacy and trust are crucial principles to address in the generic data sharing infrastructure. Organisations, people (roles), technology (hardware/software) and AI algorithms must be able to be identified and authenticated at all times.
Multiple types of data sharing methodologies can be used to feed AI algorithms. Basically, the choice can be made that data is sent to the algorithm (D2A) or that the algorithm “travels” to the data (A2D). In both cases, it is crucial that the algorithm is trusted by everyone in the ecosystem. In this proof of concept, both variants (A2D and D2A) have been applied. The A2D algorithm is also known in healthcare as the Personal Health Train.
The coalition also supports the FAIR-principles for the description of available data, in order for ‘Machine2Machine’ communication to be possible. Datasets and services are Findable, Accessible, Interoperable and Reusable. Apart from the FAIR principles, we apply the reference architecture of IDS. This makes it possible to specify per organisation, user, and algorithm which data can be used and for which reason. We explain this in more detail in the text below.

International Data Spaces (IDS)
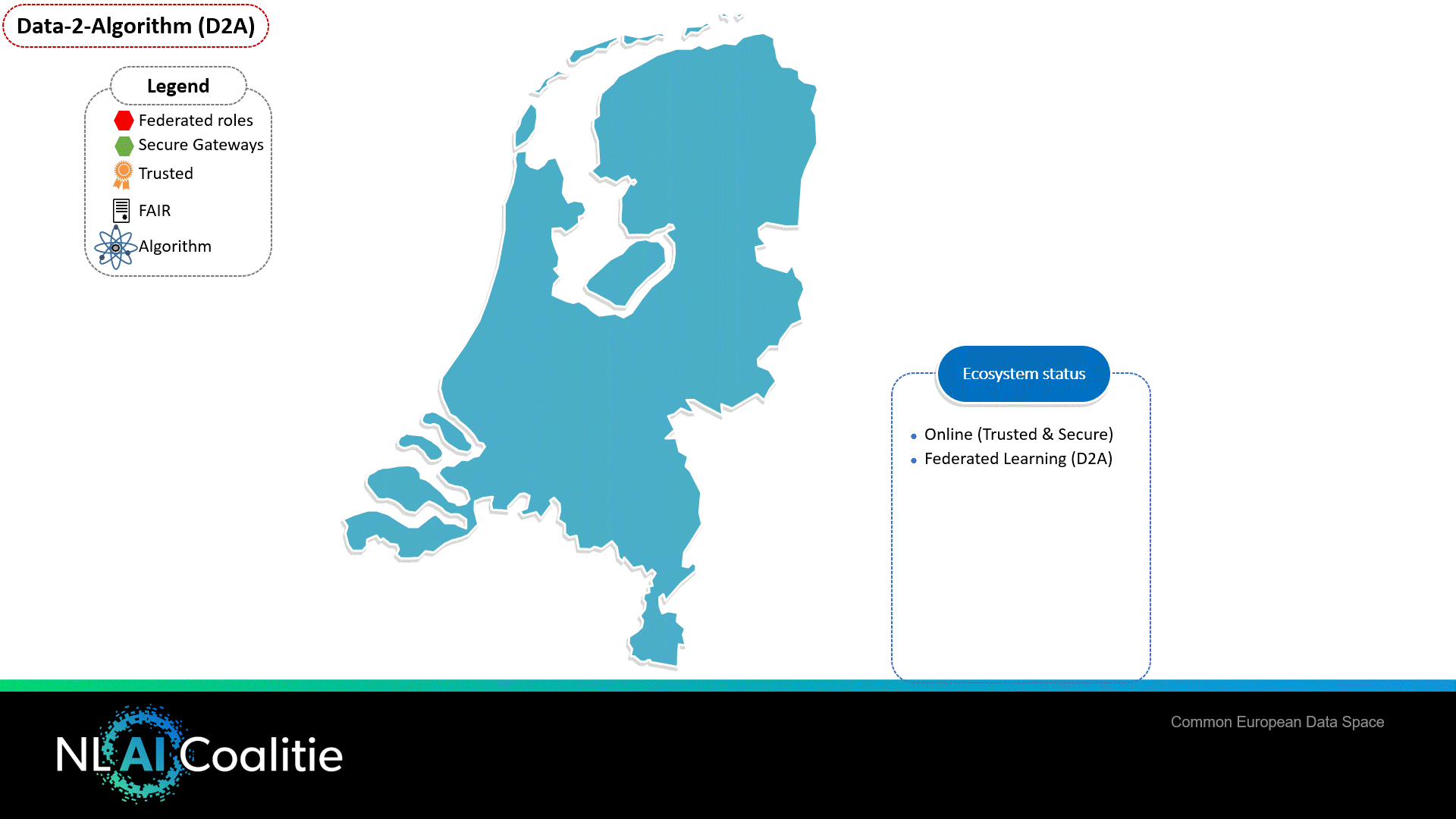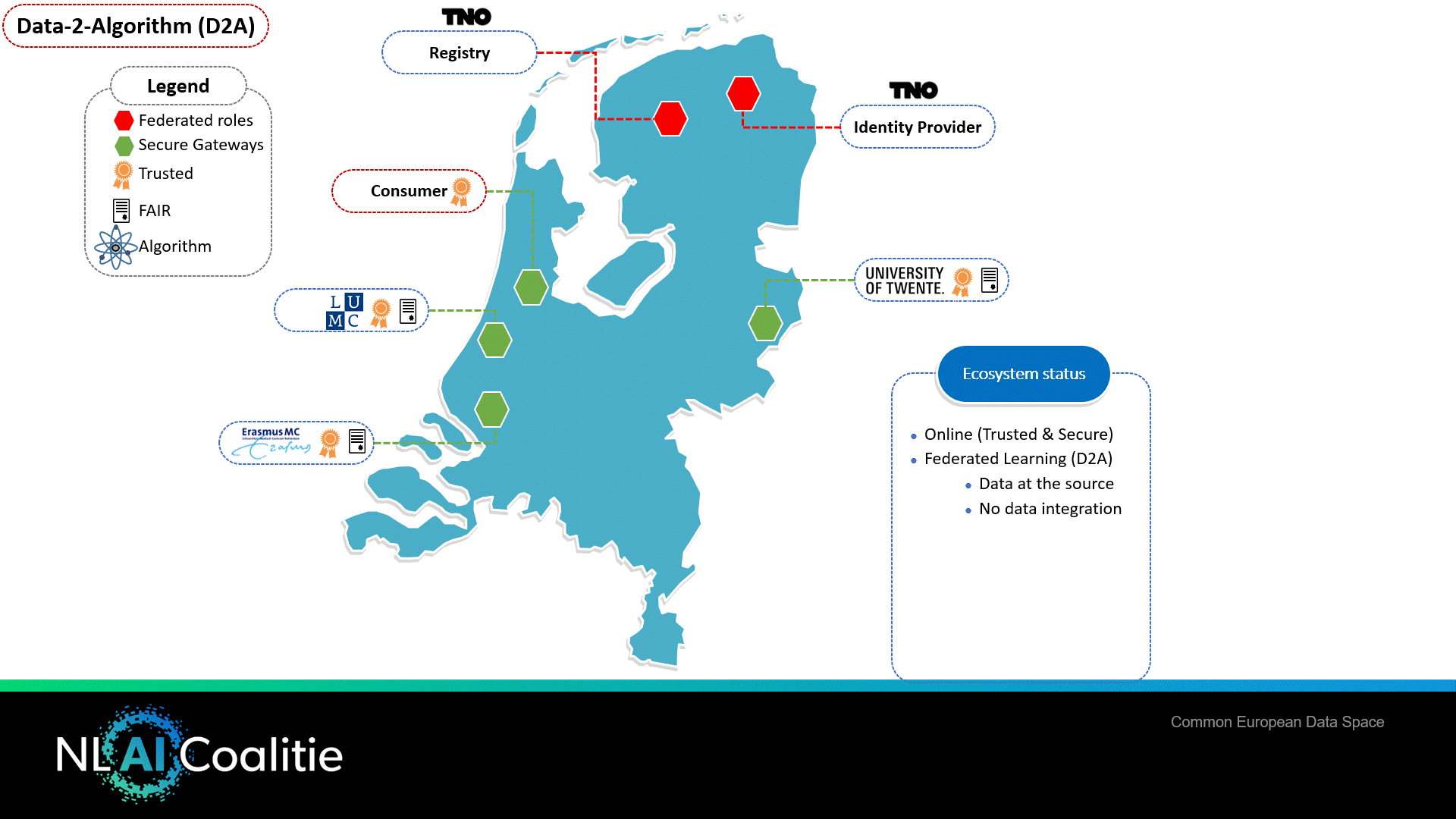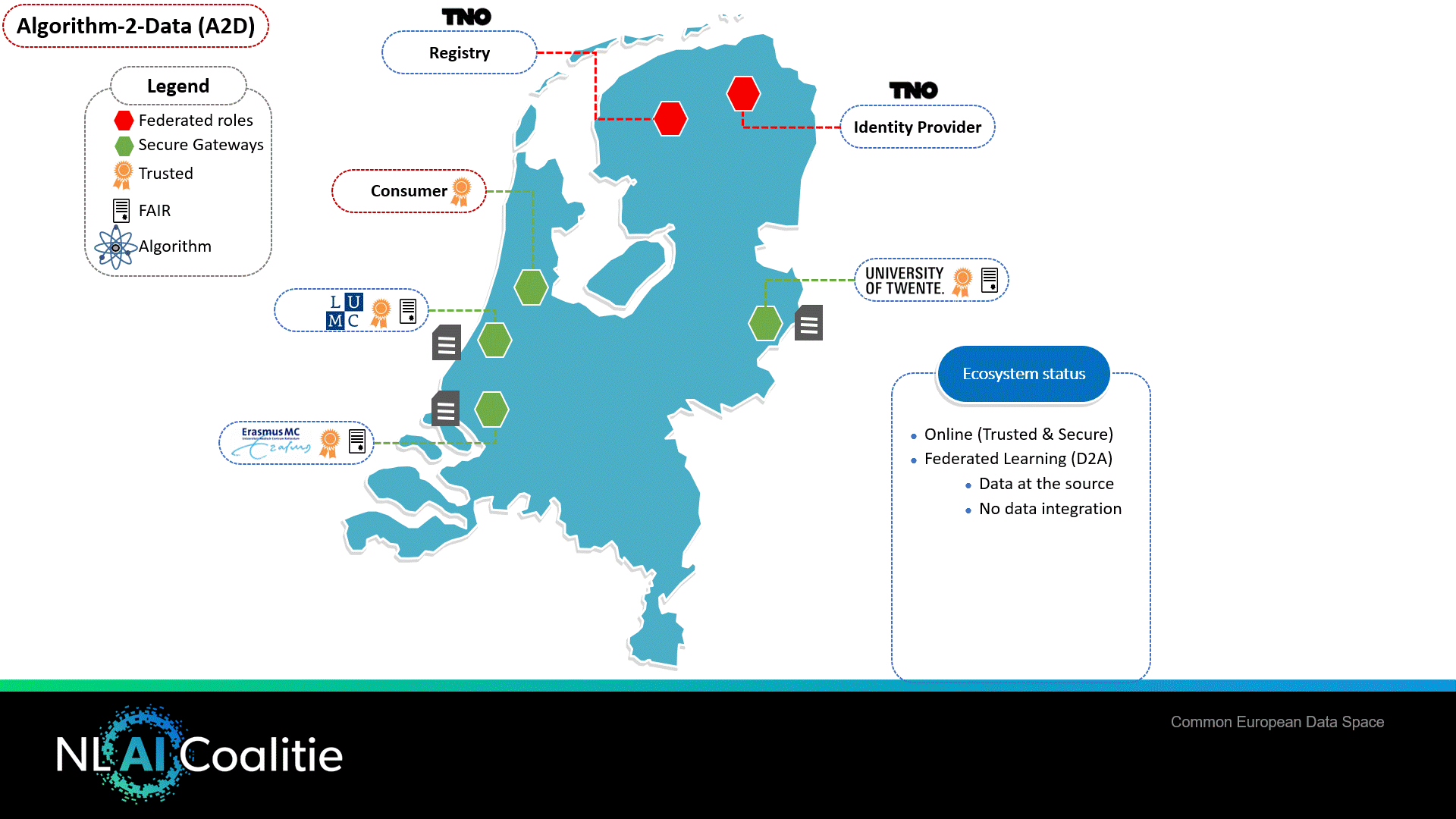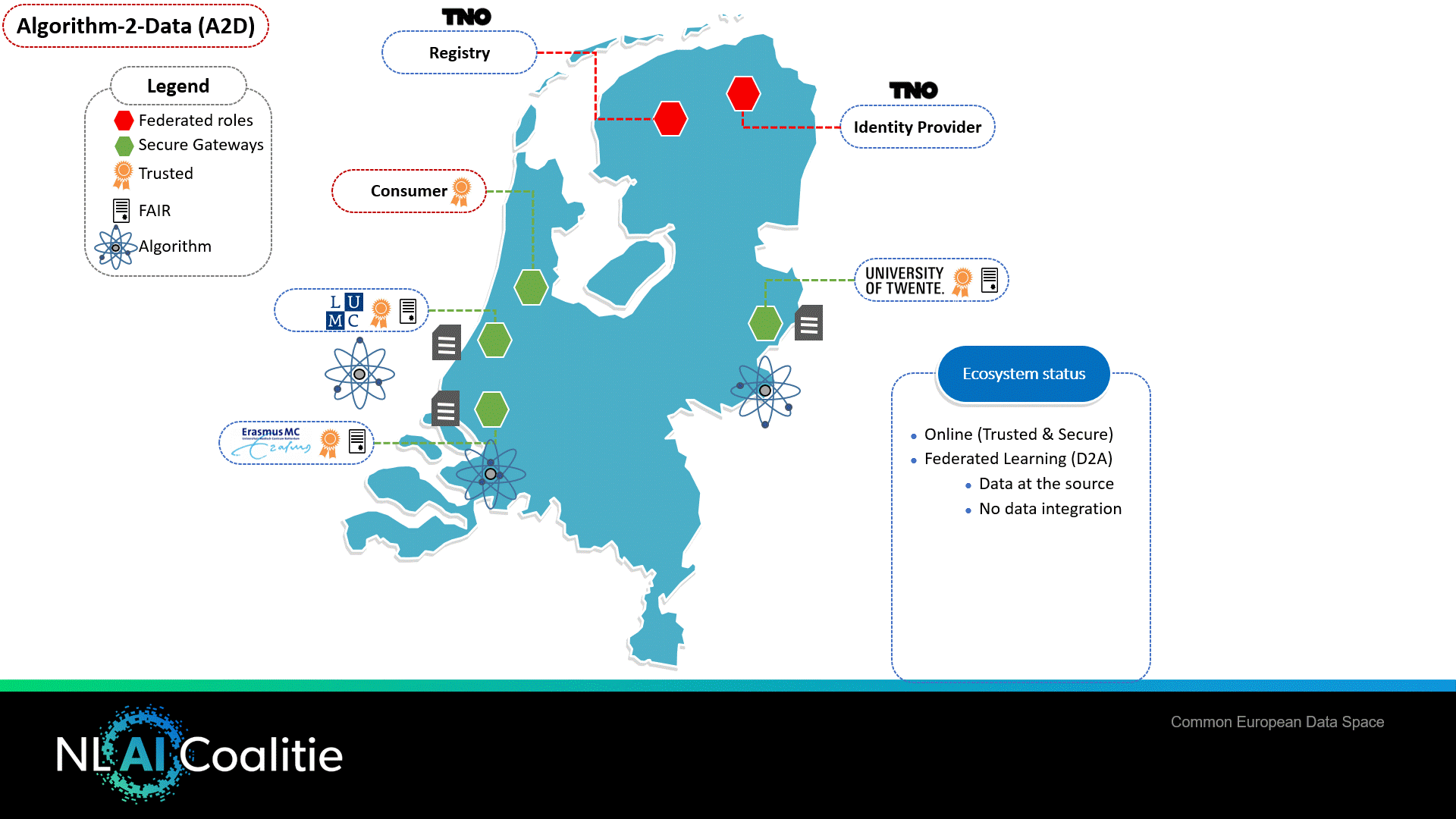
Figure 1 shows the generic data sharing infrastructure based on international standards of IDS. In this case there are three organisations that want to collaborate (LUMC, ErasmusMC & University of Twente). The ecosystem needs to be initialised, which requires a number of generic roles:
- The Identity Provider: provides digital certificates to participating organisations to ensure a “trusted ecosystem”.
- The Registry: every organisation must register within the ecosystem (publishing data services, in accordance with FAIR).
A) A participating organisation installs a ‘secure gateway’.
B) A participating organisation applies for a digital certificate for identification purposes and installs this certificate on its secure gateway.
C) The organisation registers in the ecosystem:- Is assigned a unique public identification number.
- Registers on meta level what kind of data/service is available.
Other organisations in the network can see through the register (similar to a yellow pages function) which organisations are available. They search for services/datasets on a meta-level, purchase services if desired and make agreements about data sharing (access & usage constraints). With the help of IDS it is possible to standardise (technical and governance) on the level of organisation, role, service and dataset by means of identification, authentication and authorisation.

Virus Outbreak Data Network (VODAN) – Data to Algorithm (D2A)
The data network consists of multiple data sources at different locations regarding COVID-19 specific data. A semantic data model has been made available by GO FAIR (as part of the funding of ZonMW and Philips Foundation under the VODAN-project).
Figure 2 shows how a researcher (data consumer) retrieves data from multiple FAIR data stations, where the organisations are identified and authenticated. This enables the option of authorisation at the level of information elements. A semantic model and the International Data Space roles model are used so that parties speak the same language. All actions and/or operations are technically traceable and controllable, guaranteeing (data) sovereignty.
The advantage of this solution is that with one push of a button, an organisation can connect to the network, because one semantic language is spoken. There is also a standardised way to be able to trust organisations during the period that transactions take place. This means that it becomes easier to realise reliable data connections. Implementation costs decrease and vendor lock-in is prevented.
Federated Learning – Algorithm to the Data (A2D)
The healthcare proof of concept also supports a second important variant of AI, namely sending the algorithm to the data (A2D). A common form for data sharing in AI is Federated Learning (FL). This is a distributed Machine Learning approach that meets the need not to share privacy-sensitive data over the network.
With FL, there are multiple data providers in the network, each managing their own set of data. The data consumer (and also the supplier of the FL algorithm) initiates the process and acts as the orchestrator in the learning process. FL works broadly as follows:
- All data providers run the same ML algorithm using their own ML model on their own dataset, which only contains information about the patients’ data in their own organisation.
- The individually trained model is sent by the data providers to the orchestrating server.
- The orchestrator combines the models of all individual data providers in a single model.
- The orchestrator sends the updated model back to the data providers.
- Steps 1 through 4 are repeated until the training algorithm is complete.
The result is an algorithm that is trained on more data and thus becomes more statistically reliable, assuming that the data providers can deliver good quality data.
Conclusion: AI needs a generic data component structure
The results show that it is technically possible to set up a data sharing infrastructure based on international standards (compliant with FAIR principles and IDS). It has also been shown that data does not need to be physically sent to other organisations to successfully implement AI (federative data architecture). If data is shared, it is possible that the owner of the data keeps control over the use of his or her data by means of authorisation agreements.
The application of generic standards makes it possible to share data in all kinds of environments and even between application areas. If desired, data sharing across multiple ecosystems can be realised (system or systems thinking). Data sovereignty is guaranteed by design in this architecture as well as the traceability of the transactions made. All organisations in the ecosystem are certified and therefore trusted.
This approach of a generic infrastructure for data sharing has several advantages:
- Identification, Authentication and Authorisation are standardised (via secure & trusted handshakes).
- Semantic models according to FAIR-principles are a good basis.
- Multiple types of AI algorithms can be supported while respecting privacy requirements.
Scaling up to a large-scale test environment
The above elaboration currently concerns demarcated Proof of Concepts. In the coming period, the group of stakeholders will be expanded in order to come to a large-scale test environment towards operational practice implementations. In this way, experience can be gained to realise acceleration in AI implementations. In order to stimulate the development of AI innovations, the Dutch AI Coalition makes the proof of concept software freely available via GitLab.



